参数初始化
一、参数初始化
1.1 原因
参数初始化又称为权重初始化(weight initialization)或权值初始化。参数初始化指的是在网络模型训练之前,对各个节点的权重和偏置进行初始化赋值的过程,用于解决梯度消失或者梯度爆炸,有利于模型的收敛速度和性能表现, 同时也可以加入自己相关领域的先验进行权重初始化。当定义好网络模型之后,需要进行权重初始化,恰当的权重初始化方法,可以加快模型的收敛,不恰当的初始化方法,可能导致梯度消失或爆炸,导致模型不可用。如果权重太小,则输入信号通过网络中的每一层时,其方差就会开始减小,输入最终会降低到非常低的值,导致梯度消失。如果权重太大,则输入数据的方差往往会随着每个传递层而迅速增加。最终,变得很大以至于梯度爆炸。
1.2 参数初始化方法
参数梯度不应该为0。而我们知道在全连接的神经网络中,参数梯度和反向传播得到的状态梯度以及入激活值有关——激活值饱和会导致该层状态梯度信息为0,然后导致下面所有层的参数梯度为0;入激活值为0会导致对应参数梯度为0。所以如果要保证参数梯度不等于0,那么参数初始化应该使得各层激活值不会出现饱和现象且激活值不为0。我们把这两个条件总结为参数初始化条件:
- 初始化必要条件一:各层激活值不会出现饱和现象。
- 初始化必要条件二:各层激活值不为0。
(1)全0初始化
没有隐层时, 可以将所有的参数初始化为0,即深度模型都不会使用0初始化所有参数
在神经网络中,把W初始化为0是不可以的。这是因为如果把W初始化,那么在前向传播过程中,每一层的神经元学到的东西都是一样的(激活值均为0),而在bp的时候,不同维度的参数会得到相同的更新,因为他们的gradient相同,称之为“对称失效”。同样常数初始化在这种情况也不行,因为gradient相同,weight update也相同,这样会令更新后的参数仍然保持一样的状态,但是可以初始化bias的值。
(2)标准随机初始化
希望所有参数的期望接近0。遵循这个原则,可以将参数设置为接近0的很小的随机数(有正有负),在实际中,随机参数服从高斯分布/正态分布(Gaussian distribution / normal distribution)和均匀分布(uniform distribution)都是有效的初始化方法。
但是一旦随机分布选择不当,就会导致网络优化陷入困境,引起梯度消失。
(3)Glorot条件
- 各个层的激活值h(输出值)的方差要保持一致
- 各个层对状态z的梯度的方差要保持一致
(4)参数初始化的几点要求
- 参数不能全部初始化为0,也不能全部初始化同一个值;
- 最好保证参数初始化的均值为0,正负交错,正负参数大致上数量相等;
- 初始化参数不能太大或者是太小,参数太小会导致特征在每层间逐渐缩小而难以产生作用,参数太大会导致数据在逐层间传递时逐渐放大而导致梯度消失发散,不能训练;
- 如果有可能满足Glorot条件也是不错的;
1.3 seed与随机初始化
seed在深度学习代码中叫随机种子,设置seed的目的是由于深度学习网络模型中初始的权值参数通常都是初始化成随机数。设置随机种子的方法能够近似的完全复现作者的开源深度学习代码,随机种子的选择能够减少一定程度上算法结果的随机性,即产生随机种子意味着每次运行实验,产生的随机数都是相同的吗,给复现算法提供了极大的帮助!
随机种子的设定对大部分的模型并不会产生特别大的实质性影响,神经网络更多会和迭代次数,学习率等相关。然而对于预训练模型而言,非常依赖参数的随机初始化过程,那么,随机种子的设定就显得非常重要。
随机种子输入分布生成函数tensor.normal_ , tensor.uniform_ 等,从而产生神经网络初始化参数。
二、Xavier初始化
“Xavier”初始化方法是 2010 年提出的,针对有非线性激活函数时的权值初始化方法,是工程tricks中的一种,方法来源于论文《Understanding the difficulty of training deep feedforward neural networks》,目的是为了使得网络中信息更好的流动,每一层输出的方差应该尽量相等。
- 目标是保持数据的方差维持在 1 左右
- 针对饱和激活函数如 sigmoid 和 tanh 等。
整个大型前馈神经网络无非就是一个超级大映射,将原始样本稳定的映射成它的类别。也就是将样本空间映射到类别空间。试想,如果样本空间与类别空间的分布差异很大,比如说类别空间特别稠密,样本空间特别稀疏辽阔,那么在类别空间得到的用于反向传播的误差丢给样本空间后简直变得微不足道,也就是会导致模型的训练非常缓慢。同样,如果类别空间特别稀疏,样本空间特别稠密,那么在类别空间算出来的误差丢给样本空间后简直是爆炸般的存在,即导致模型发散震荡,无法收敛。因此,我们要让样本空间与类别空间的分布差异(密度差别)不要太大,也就是要让它们的方差尽可能相等。
优势:
- 梯度消失和爆炸:在深度网络中,梯度消失和梯度爆炸是一个常见的问题。如果每一层都将方差放大,那么在多层网络中,梯度可能会很快增长至非常大的值(爆炸),或者减小至接近零(消失)。Xavier 初始化试图使得每一层的输出的方差接近于其输入的方差,从而避免梯度消失或梯度爆炸的问题。
- 加速收敛:Xavier 初始化使得每一层的输出的方差接近于其输入的方差,从而使得每一层的梯度的方差接近于 1。这样,每一层的参数更新的幅度就不会相差太大,从而加速收敛。
劣势:
Xavier初始化主要用于tanh,softsign等奇函数、线性函数(Taylor展开),不适用于ReLU,sigmod函数等非奇函数、线性函数。
原因在于Xavier方法的推导过程基于两点假设:
- (1) 激活函数是线性的,因此并不适应于ReLU,sigmoid等非线性激活函数
- (2) 激活函数是关于0对称(奇函数)的,因此不适应于ReLU,sigmoid等不是关于0对称的激活函数
三、kaiming初始化
Kaiming初始化的发明人kaiming he,在Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification论文中提出了针对relu的kaiming初始化。
Xavier在tanh函数上表现可以,但对 ReLU 等激活函数效果不好,何凯明引入了一种更鲁棒的权重初始化方法–He Initialization。
He Initialization也有两种变体:
He Normal:正态分布的均值为0、方差为sqrt( 2/fan_in )。
He Uniform:均匀分布的区间为【-sqrt( 6/fan_in) , sqrt(6/fan_in) 】
He Initialization适用于使用ReLU、Leaky ReLU这样的非线性激活函数的网络。
He Initialization和Xavier Initialization 两种方法都使用类似的理论分析:它们为从中提取初始参数的分布找到了很好的方差。该方差适用于所使用的激活函数,并且在不明确考虑分布类型的情况下导出。
四、pytorch参数初始化方法
pytorch中的各种参数层(Linear、Conv2d、BatchNorm等)在__init__方法中定义后,不需要手动初始化就可以直接使用,这是因为Pytorch对这些层都会进行默认初始化, 绝大部分为kaiming初始化yyds。
初始化函数
1 | |
kaiming_uniform_按照均匀分布初始化tensor,在U (−bound, bound)中采样,其中
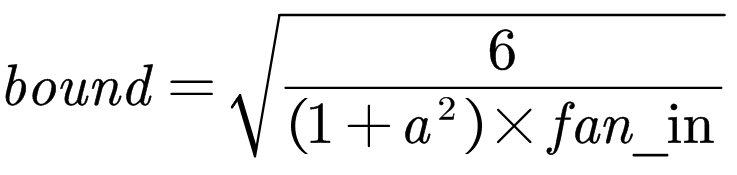
同样的,fan_in在tensor为二维时,是tensor.size(1),注意,上面给出的初始化公式均是在mode和nonlinearity在默认参数下的结果
Linear的初始化
Linear自带的初始化函数为
1 | |
W在U (−bound, bound)中采样,其中
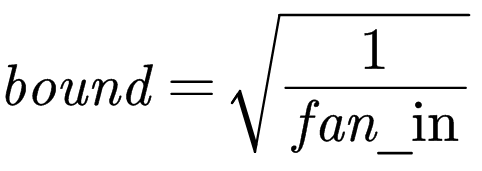
fan_in即为W的第二维大小,即Linear所作用的输入向量的维度
bias也在U (−bound,bound)中采样,且bound与W一样
Conv的初始化
以二维为例,卷积层的参数实际上是一个四维tensor:
1 | |
比如一个输入channel为3,输出channel为64,kernel size=3的卷积层,其权值即为一个3×64×3×3的向量,它会这样进行初始化:
1 | |
同样默认使用kaiming_uniform,在U (−bound, bound)中采样,其中
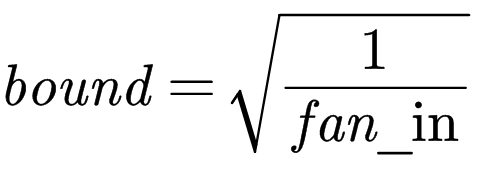
对于fan_in的计算:
1 | |
即: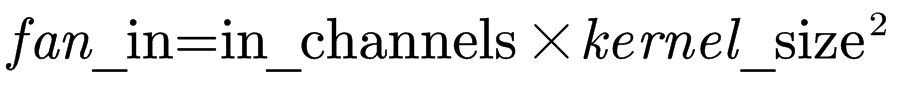
BatchNorm层初始化
1 | |
weight初始化为U (0, 1) ,bias初始化为0
ResNet初始化
Resnet在定义各层之后,pytorch官方代码的__init__方法会对不同的层进行手动的初始化:
1 | |
首先对于所有卷积层,与之前不同,这里采用的mode是fan_out,nonlinearity是relu,且使用的初始化函数为kaiming_normal_,即参数在N (0,std)中采样,其中
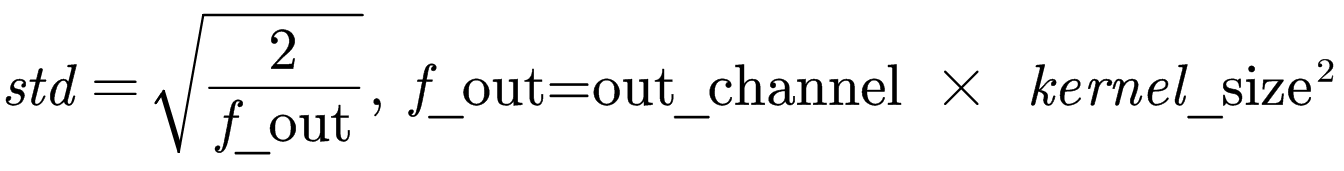
卷积层的bias这里没有提到,因此采用的仍然是默认的初始化方法,而BatchNorm和GroupNorm的weight均初始化为1,bias初始化为0,区别于默认的weight在0~1中均匀采样,bias为0,剩下的Linear层未被提到,仍然采用默认的初始化方法
VGG
VGG的pytorch官方初始化方法如下:
1 | |
卷积层的初始化方法同ResNet,只不过bias初始化为0,BatchNorm层初始化方法同ResNet,Linear层的weight初始化为N ( 0 , 0.01 ) N(0,0.01)N(0,0.01),bias初始化为0
五、pytorch初始化api
初始化方法汇总
PyTorch 中提供了 11种初始化方法:
- Xavier 均匀分布
- Xavier 正态分布
- Kaiming 均匀分布
- Kaiming 正态分布
- 均匀分布
- 正态分布
- 常数分布
- 正交矩阵初始化
- 单位矩阵初始化
- 稀疏矩阵初始化
- 狄拉克δ函数初始化
torch.nn.init.uniform_(tensor, a=0.0, b=1.0)
含义:从均匀分布 U ( a , b ) U(a, b)U(a,b)中生成值,填充输入的张量
参数:
(1)tensor - n 维的 torch.Tensor
(2)a - 均匀分布的下界
(3)b - 均匀分布的上界
1 | |
torch.nn.init.normal_(tensor, mean=0, std=1)
含义:从给定均值和标准差的正态分布 N ( m e a n , s t d ) N(mean, std)N(mean,std)中生成值,填充输入的张量或变量
参数:
(1)tensor – n 维的 torch.Tensor
(2)mean – 正态分布的均值
(3)std – 正态分布的标准差
1 | |
torch.nn.init.constant_(tensor, val)
含义:用 val 的值填充输入的张量或变量
参数:
(1)tensor – n 维的 torch.Tensor
(2)val – 用来填充张量的值
1 | |
torch.nn.init.eye_(tensor)
含义:用单位矩阵来填充 2 维输入张量或变量。在线性层尽可能多的保存输入特性。
参数:
(1)tensor – 2 维的 torch.Tensor
1 | |
torch.nn.init.dirac_(tensor)
含义:用 Dirac δ 函数来填充{3, 4, 5}维输入张量或变量。在卷积层尽可能多的保存输入通道特性。
参数:
(1)tensor – {3, 4, 5}维的 torch.Tensor
1 | |
torch.nn.init.xavier_uniform_(tensor, gain=1)
含义:用一个均匀分布生成值,填充输入的张量或变量。结果张量中的值采样自 U(-a, a), 该方法也被称为 Glorot initialisation。
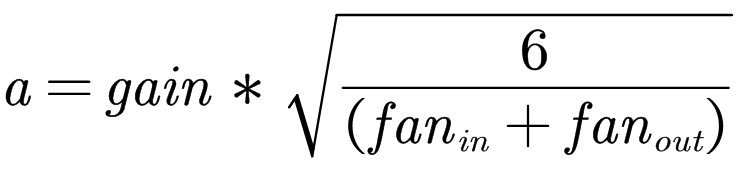
参数:
(1)tensor – n 维的 torch.Tensor
(2)gain - 可选的缩放因子
1 | |
torch.nn.init.xavier_normal_(tensor, gain=1):
含义:用一个正态分布生成值,填充输入的张量或变量。结果张量中的值采样自:
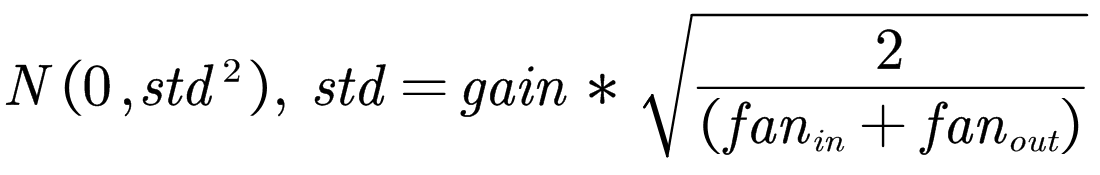
参数:
(1)tensor – n 维的 torch.Tensor
(2)gain - 可选的缩放因子
1 | |
torch.nn.init.kaiming_uniform_(tensor, a=0, mode=’fan_in’, nonlinearity=’leaky_relu’)
含义:用一个均匀分布生成值,填充输入的张量或变量。结果张量中的值采样自 U(-bound, bound),其中
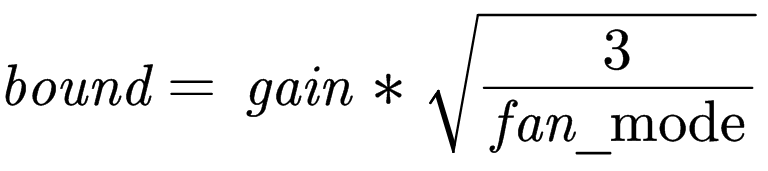
参数:
(1)tensor:n 维的 torch.Tensor
(2)a:leaky_relu的负斜率,只有在nonlinearity=’leaky_relu’时候起作用
(3)mode:fan_in或者fan_out。fan_in保留forward传递中权重的方差大小,fan_out保留backward传递中权重的方差大小
(4)nonlinearity:nn.functional名称,推荐使用relu和leaky_relu。
1 | |
torch.nn.init.kaiming_normal_(tensor, a=0, mode=’fan_in’, nonlinearity=’leaky_relu’)
含义:用一个均匀分布生成值,填充输入的张量或变量。结果张量中的值采样自 U(-bound, bound),其中
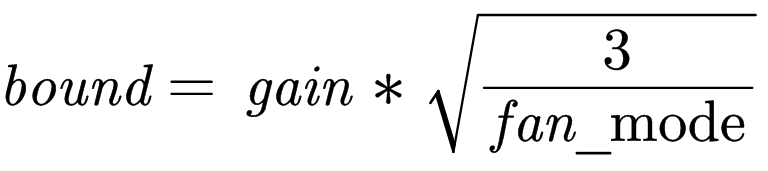
参数:
(1)tensor:n 维的 torch.Tensor
(2)a:leaky_relu的负斜率,只有在nonlinearity=’leaky_relu’时候起作用
(3)mode:fan_in或者fan_out。fan_in保留forward传递中权重的方差大小,fan_out保留backward传递中权重的方差大小
(4)nonlinearity:nn.functional名称,推荐使用relu和leaky_relu。
1 | |
torch.nn.init.kaiming_normal_(tensor, a=0, mode=’fan_in’, nonlinearity=’leaky_relu’)
含义:用一个正态分布生成值,填充输入的张量或变量。结果张量中的值采样自:
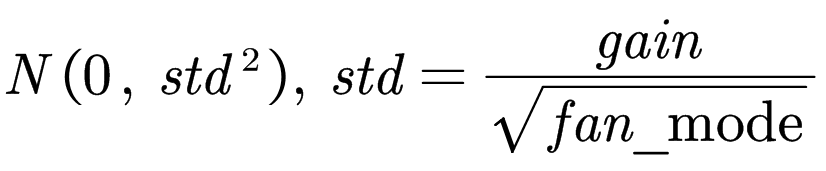
参数:
(1)tensor:n 维的 torch.Tensor
(2)a:leaky_relu的负斜率,只有在nonlinearity=’leaky_relu’时候起作用
(3)mode:fan_in或者fan_out。fan_in保留forward传递中权重的方差大小,fan_out保留backward传递中权重的方差大小
(4)nonlinearity:nn.functional名称,推荐使用relu和leaky_relu。
1 | |
torch.nn.init.sparse_(tensor, sparsity, std=0.01)
含义:将 2 维的输入张量或变量当做稀疏矩阵填充,结果张量中的值采样自N(0,0.01),其中非零元素根据一个均值为 0,标准差为 std 的正态分布生成。
参数:
(1)tensor – n 维的 torch.Tensor
(2)sparsity - 每列中需要被设置成零的元素比例
(3)std - 用于生成非零值的正态分布的标准差
1 | |
torch.nn.init.orthogonal_(tensor, gain=1)
含义:用一个(半)正交矩阵初始化输入张量,参考Saxe, A. et al. (2013) - Exact solutions to the nonlinear dynamics of learning in deep linear neural networks。输入张量必须至少有2维,对于大于2维的张量,超出的维度将被flatten化。正交初始化可以使得卷积核更加紧凑,可以去除相关性,使模型更容易学到有效的参数。
参数:
(1)tensor – n维需要初始化的张量,其中n>=2
(2)gain -可选放缩因子
1 | |
自定义初始化
可以用apply()函数初始化,可选用pytorch提供的多种初始化函数,apply函数会递归地搜索网络内的所有module并把参数表示的函数应用到所有的module上。
1 | |
参考:
- 深度学习——Xavier初始化方法_xavier_uniform_-CSDN博客
- 深度前馈网络与Xavier初始化原理
- 深度学习:Xavier and Kaiming Initialization
- 【精选】PyTorch中的Xavier以及He权重初始化方法解释_pytorch中he初始化-CSDN博客
- 深度学习之参数初始化
- Pytorch 默认参数初始化_pytorch中默认的参数初始化-CSDN博客
- PyTorch常用函数(8)_nn.init.calculate_gain-CSDN博客
- seed在模型中的应用及用法_模型的seed什么作用_zyrlia的博客-CSDN博客
- 【调参侠的修炼笔记2】随机种子Seed的讲人话解释
- 模型初始化与随机种子——Pytorch 炼丹技巧(随手记)_pytorch需要随机初始化吗-CSDN博客
- 权重/参数初始化方法
- 如何选择合适的初始化方法 | 神经网络的初始化方法总结