主动学习笔记
概念
Burr Settles的文章《Active Learning Literature Survey》详细地介绍了主动学习:“主动学习是机器学习的一个子领域,在统计学领域也叫查询学习或最优实验设计”。为解决某些任务数据标签较少或打标签“代价”较高的问题而出现。主动学习方法尝试解决样本的标注瓶颈,通过主动优先选择最有价值的未标注样本进行标注,以尽可能少的标注样本达到模型的预期性能。其主要方式是模型通过与用户或专家进行交互,抛出”query”(unlabel data)让专家确定数据的标签,如此反复,以期让模型利用较少的标记数据获得较好“性能”。
主动学习方法是一个迭代式的交互训练过程,主要由五个核心部分组成,包括:未标注样本池(unlabeled pool,记为U)、筛选策略(select queries,记为Q)、标注者(human annotator,记为S),标注数据集(labeled training set,记为L),目标模型(machine learning model,记为G)。
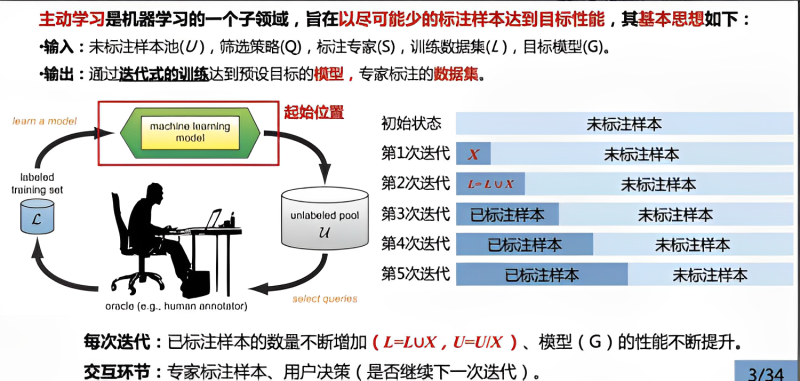
active learning与passive learning最大的不同是passive learning或supervised learning其首先就需要大量的专家标注样本训练模型,而active learning则是利用少量标注样本,大量未标注样本训练模型,然后由learner选择样本返回给Oracle或expert打标签,进而不断迭代以获得较好的模型,该过程必须要有专家的参与,这也是active learning区别于semi-supervised learning的不同之处。
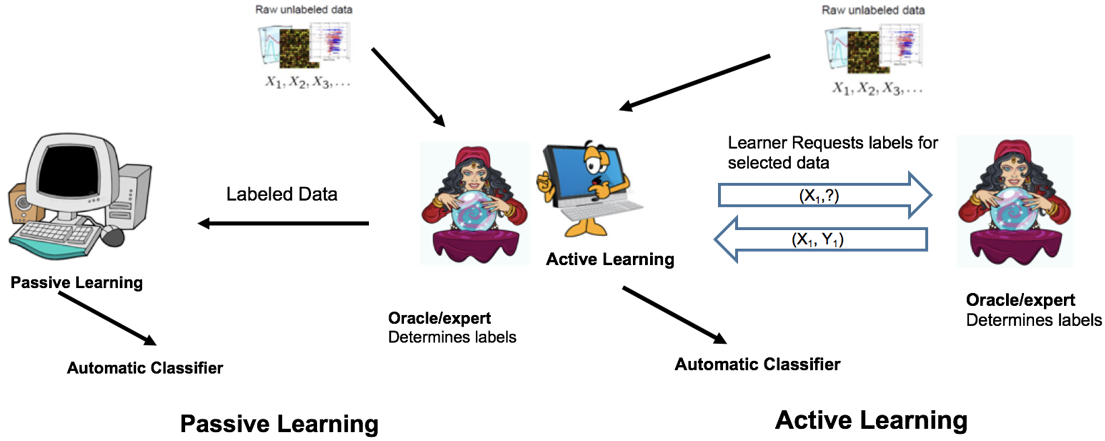
半监督学习一般不需要人工参与,是通过具有一定分类精度的基准分类器实现对未标注样例的自动标注;而主动学习有别于半监督学习的特点之一就是需要将挑选出的高价值样例进行人工准确标注。
场景
membership query synthesis
query samples可以为任意样本或随机生成(例如对图片样本进行旋转或添加“噪声”等,类似样本增强的策略),然后将其送个Oracle进行判断,策略并不是在数据池中挑选样本进行查询,而是自行生成新样本进行查询。其过程如下所示:
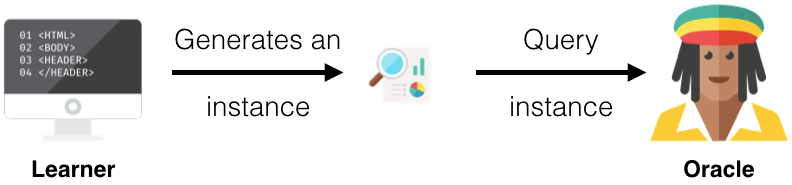
由于在样本的随机生成过程中,其有较大的不确定性,因此在某些应用,如NLP中其生成的结果无任何意义,同时专家也无法标记,故这种方法对于某些应用场景有一定的局限性。
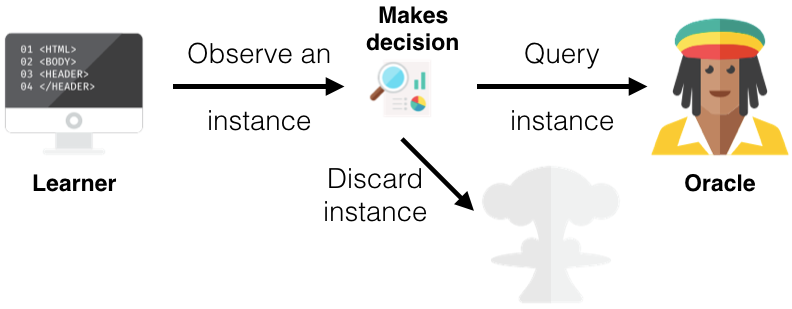
stream-based selective sampling
假设样本的获得是“免费的”或代价较小的,数据以数据流的形式输入,主动学习策略需要确定对当前数据进行标记还是直接用现有模型预测。learner每次基于某种query strategy选择一个样本给专家进行标记,模型通过某种“informativeness measure”确定是否由专家标注样本,或舍弃该样本。如下:
pool-based sampling
Pool-Based Sampling每次确定一批unlabeled data,由专家标记。Pool-Based Sampling是active learning中应用最为广泛的一种framework。
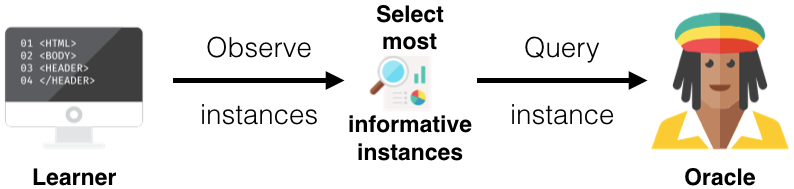
Query Strategy
如上文所述,learner需要根据一定的策略选择unlabeled data,在active learning中其主要包括以下几种:
(1) Uncertainty Sampling
Uncertainty Sampling是最为广泛的一种query strategy(类似hard sample mining),其主要是将模型“最易混淆”或“信息量”最大、最有价值的样本返回给expert,以期获得较大的增益,用entropy衡量。
(2) Query-By—Committe
Query-By—Committe的思想类似于模型集成和投票,不同的模型即为Committee,投票的divergence最大的样本即为“controversial sample”,利用vote entropy衡量。
(3) Expected Model Change
Expected Model Change其主要思想即对模型“改变”最大的标记样本为“有价值”的样本,这里对模型“改变”的衡量可以由梯度提升来体现,如“expected gradient length” (EGL)。
(4) Expected Error Reduction
类似与Expect Model Change,Expected Error Reduction的思想是通过增加一个标注的样本其loss减小最多。
(5) Variance Reduction
Expected Error Reduction需要判断每个样本对模型的“贡献程度”,其“成本”较高,而Variance Reduction其主要思想是使variance最小的样本,其“价值”最大。
(6) Density-Weighted Methods
由uncertain strategy确定的样本其更多的是关注单个样本对模型的提升或“贡献”程度,然而很多候,其“模糊”的样本往往会是一些outliers或噪声,若让模型更多的关注或学习这些样本,其对性能的提升将不会产生帮助,在考虑individual时同时还需关注整体样本的分布,故提出了Density-Weighted Methods。
参考: